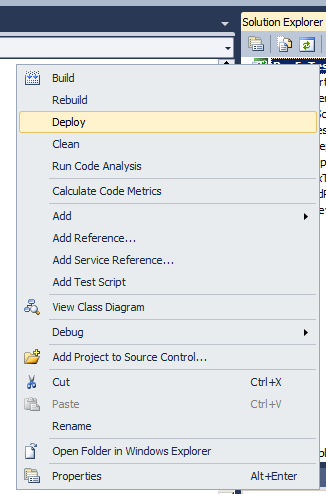
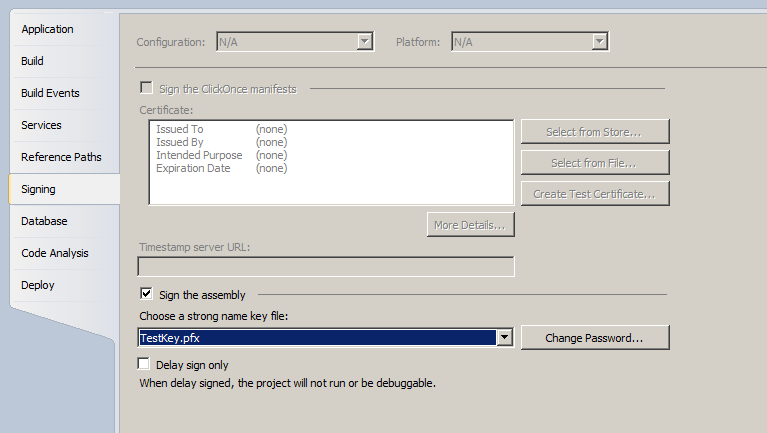
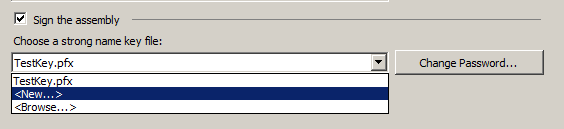
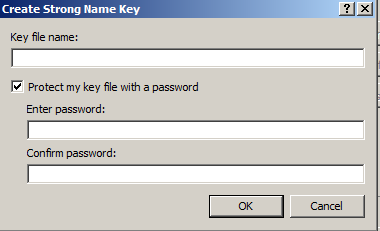
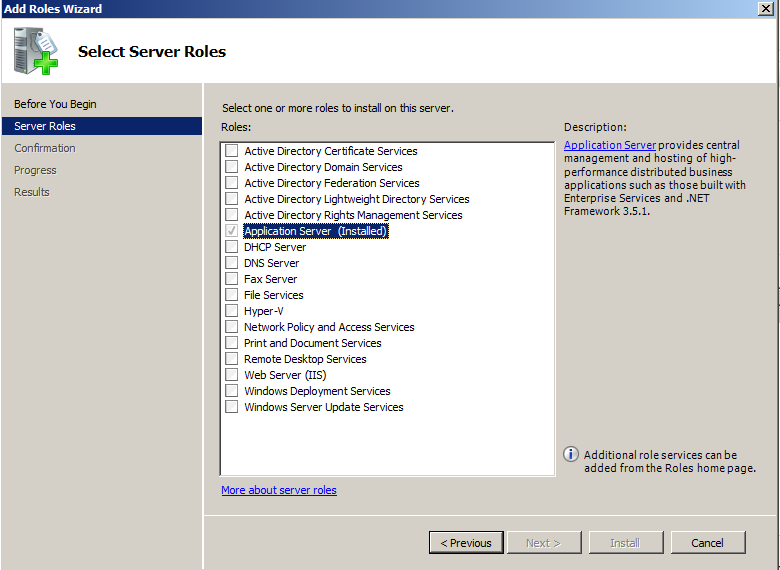
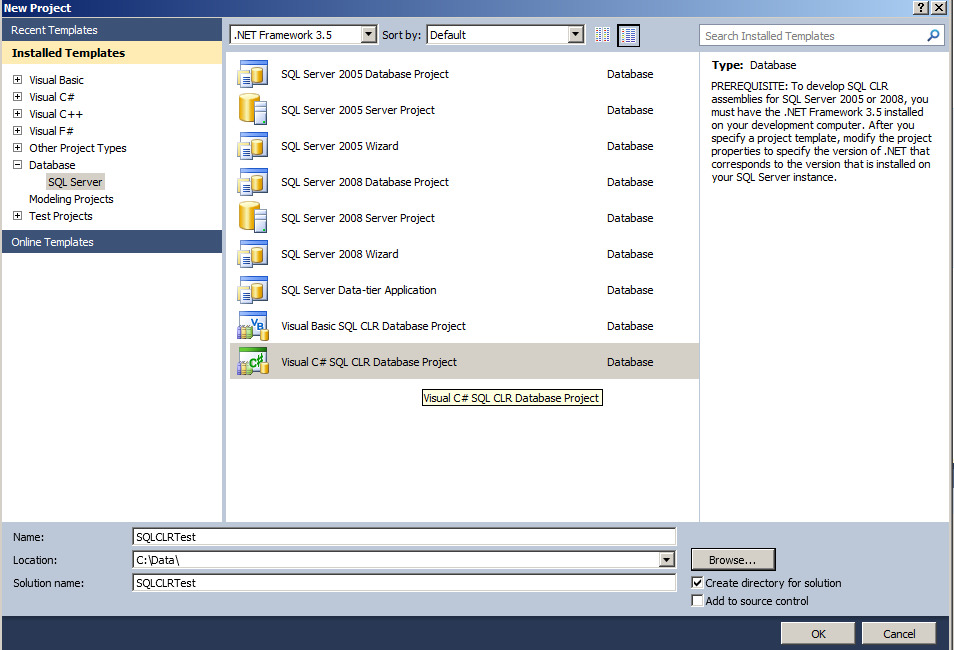
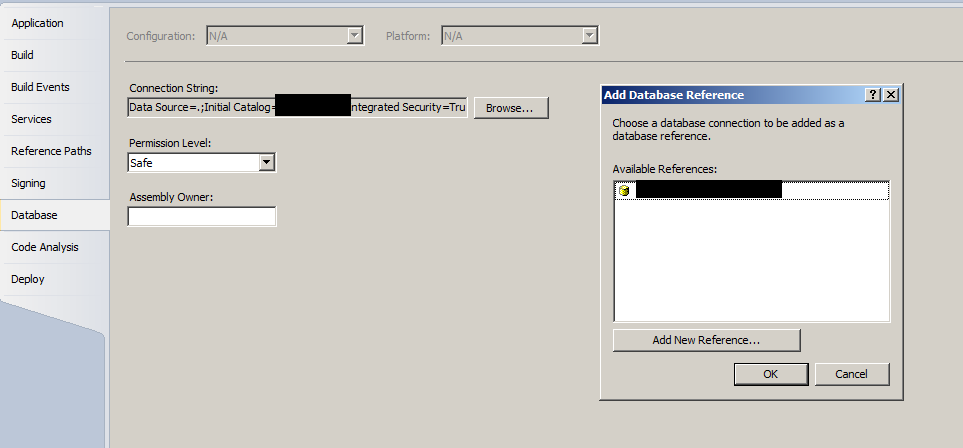
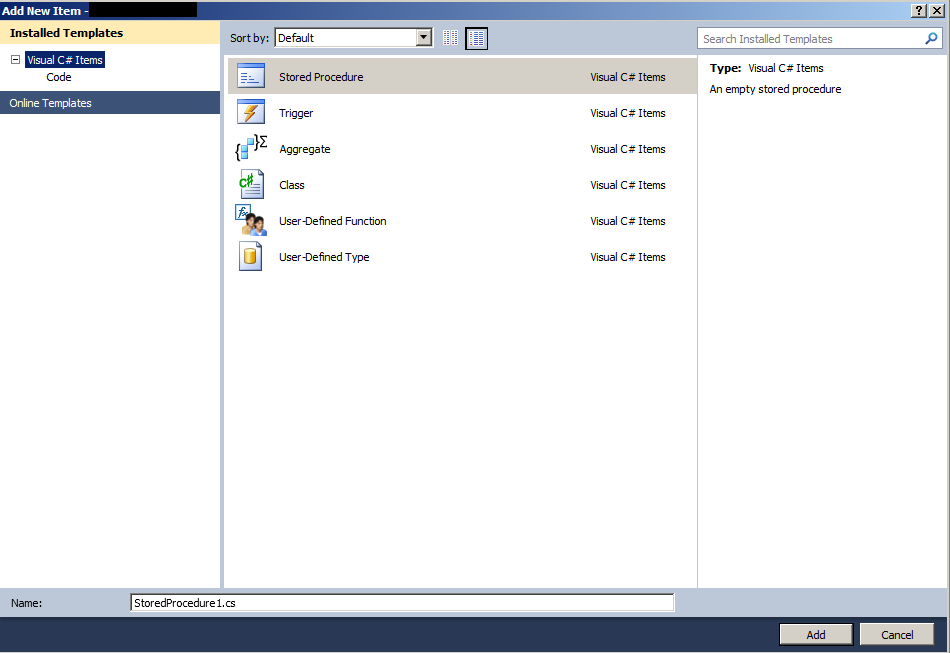
SET NOCOUNT ON;
-- Constants
DECLARE @BACKUP_DAYS_THRESHOLD INT = 8,
@NEW_BACKUP_FILE_LOCATION VARCHAR(256) = 'C:\Temp\BackupFileCopies\',
@DATAFILE_RESTORATION_LOCATION VARCHAR(256) = 'C:\Temp\DataFileRestores\',
@DB_MAIL_PROFILENAME SYSNAME = 'Database Administrators',
@EMAIL_RECIPIENTS VARCHAR(1000) = 'yourEmail@yourDomain.com'
-- Retrieve List of Last Full Backups and their Backup Files
IF OBJECT_ID('TempDB..#lastBackupsTaken') IS NOT NULL
DROP TABLE [#lastBackupsTaken]
CREATE TABLE [#lastBackupsTaken]
(
[serverName] VARCHAR(256),
[databaseName] VARCHAR(256),
[physicalFileSpec] VARCHAR(256),
[backupFinishDate] DATETIME
)
INSERT INTO
[#lastBackupsTaken]
(
[serverName],
[databaseName],
[physicalFileSpec],
[backupFinishDate]
)
SELECT
@@SERVERNAME,
[BackupSets].[database_name],
[MediaFamily].[physical_device_name],
[BackupSets].[backup_finish_date]
FROM
[msdb].[dbo].[backupset] AS BackupSets
INNER JOIN (
SELECT
[database_name],
MAX([backup_start_date]) AS MaxBackup_Start_Date
FROM
[msdb].[dbo].[backupset]
WHERE
[type] = 'D'
AND [backup_finish_date] IS NOT NULL
GROUP BY
[database_name]
) AS Constrained ON
[BackupSets].[database_name] = [Constrained].[database_name]
AND [BackupSets].[backup_start_date] = [Constrained].[MaxBackup_Start_Date]
AND [BackupSets].[type] = 'D'
INNER JOIN [msdb].[dbo].[backupmediafamily] AS MediaFamily ON
[BackupSets].[media_set_id] = [MediaFamily].[media_set_id]
-- Retrieve List of the FileGroups in the Databases as of the Last Full Backups
IF OBJECT_ID('TempDB..#logicalFilesForlastBackupsTaken') IS NOT NULL
DROP TABLE [#logicalFilesForlastBackupsTaken]
CREATE TABLE [#logicalFilesForlastBackupsTaken]
(
[serverName] VARCHAR(256),
[databaseName] VARCHAR(256),
[logicalName] VARCHAR(256)
)
INSERT INTO
[#logicalFilesForlastBackupsTaken]
SELECT
@@SERVERNAME,
[BackupSets].[database_name],
[LogicalFiles].[logical_name]
FROM
[msdb].[dbo].[backupset] AS BackupSets
INNER JOIN (
SELECT
[database_name],
MAX([backup_start_date]) AS MaxBackup_Start_Date
FROM
[msdb].[dbo].[backupset]
WHERE
[type] = 'D'
AND [backup_finish_date] IS NOT NULL
GROUP BY
[database_name]
) AS Constrained ON
[BackupSets].[database_name] = [Constrained].[database_name]
AND [BackupSets].[backup_start_date] = [Constrained].[MaxBackup_Start_Date]
INNER JOIN [msdb].[dbo].[backupfile] AS LogicalFiles ON
[BackupSets].[backup_set_id] = [LogicalFiles].[backup_set_id]
AND [LogicalFiles].[is_present] = 1
-- Create a list of all databases we are going to restore and Consistency Check (DBCC CHECKDB)
IF OBJECT_ID('TempDB..#databasesToCheck') IS NOT NULL
DROP TABLE [#databasesToCheck]
CREATE TABLE [#databasesToCheck]
(
[databaseName] VARCHAR(256),
[executionOrder] INT IDENTITY(1,1)
)
INSERT INTO
[#databasesToCheck]
(
[databaseName]
)
SELECT
[databaseName]
FROM
[#lastBackupsTaken]
WHERE
[databaseName] NOT IN (
'master',
'tempdb'
)
GROUP BY
[databaseName]
-- For each database in the list, copy the backup files, run a Red-Gate Hyperbac Virtual Restore, Run Consistency Check, Record the results, and then drop the database
DECLARE @currentDBIdentifier INT,
@maxDBIdentifier INT,
@currentDBName VARCHAR(256),
@lastBackupTime DATETIME,
@statusMessage VARCHAR(MAX) = '',
@statusCode INT = 0,
@errorMessage VARCHAR(MAX) = '',
@messageSubject VARCHAR(256),
@sql VARCHAR(MAX) = '',
@backupCopyResults VARCHAR(MAX) = '',
@currentBackupFileIdentifier INT,
@maxBackupFileIdentifier INT,
@commandLine VARCHAR(2000),
@databaseWasRestored BIT = 0
IF OBJECT_ID('TempDB..#backupFilesToHandle') IS NOT NULL
DROP TABLE [#backupFilesToHandle]
CREATE TABLE [#backupFilesToHandle]
(
[oldFileSpec] VARCHAR(256),
[newFileSpec] VARCHAR(256),
[executionOrder] INT IDENTITY(1,1)
)
IF OBJECT_ID('TempDB..#commandLineResults') IS NOT NULL
DROP TABLE [#commandLineResults]
CREATE TABLE [#commandLineResults]
(
[outputLine] NVARCHAR(255)
)
IF OBJECT_ID('TempDB..#checkDBResults') IS NOT NULL
DROP TABLE [#checkDBResults]
CREATE TABLE [#checkDBResults]
(
[ServerName] [varchar](100) NULL,
[DatabaseName] [varchar](256) NULL,
[Error] [varchar](256) NULL,
[Level] [varchar](256) NULL,
[State] [varchar](256) NULL,
[MessageText] [varchar](7000) NULL,
[RepairLevel] [varchar](256) NULL,
[Status] [varchar](256) NULL,
[DbId] [varchar](256) NULL,
[Id] [varchar](256) NULL,
[IndId] [varchar](256) NULL,
[PartitionId] [varchar](256) NULL,
[AllocUnitId] [varchar](256) NULL,
[File] [varchar](256) NULL,
[Page] [varchar](256) NULL,
[Slot] [varchar](256) NULL,
[RefFile] [varchar](256) NULL,
[RefPage] [varchar](256) NULL,
[RefSlot] [varchar](256) NULL,
[Allocation] [varchar](256) NULL,
[insert_date] [datetime] NULL
)
-- Begin Database Loop
SELECT
@currentDBIdentifier = MIN([executionOrder]),
@maxDBIdentifier = MAX([executionOrder])
FROM
[#databasesToCheck]
WHILE (@currentDBIdentifier < @maxDBIdentifier) BEGIN SELECT @currentDBName = [databaseName] FROM [#databasesToCheck] WHERE [executionOrder] = @currentDBIdentifier -- Let's make sure the last database backup isn't too old (in case some third-party script clears off old database backups) SELECT @lastBackupTime = MAX([backupFinishDate]) FROM [#lastBackupsTaken] WHERE [databaseName] = @currentDBName IF (DATEDIFF(DAY,@lastBackupTime,GETDATE()) > @BACKUP_DAYS_THRESHOLD)
BEGIN
-- The oldest backup for this database was taken too long ago
SET @statusMessage = @statusMessage + 'DBCC FOR ' + @currentDBName + ' was not properly performed (Last Backup Too Old)
'
SET @statusCode = @statusCode + 1
END
ELSE
BEGIN
-- Prepare the Backup Files
TRUNCATE TABLE [#backupFilesToHandle]
INSERT INTO
[#backupFilesToHandle]
(
[oldFileSpec],
[newFileSpec]
)
SELECT
[physicalFileSpec],
@NEW_BACKUP_FILE_LOCATION + SUBSTRING([physicalFileSpec],((LEN([physicalFileSpec]))-(CHARINDEX('\',REVERSE([physicalFileSpec])))+2),(CHARINDEX('\',REVERSE([physicalFileSpec])))-1)
FROM
[#lastBackupsTaken]
WHERE
[databaseName] = @currentDBName
-- Start the restore script and copy the backup files
SET @sql = 'RESTORE DATABASE [' + @currentDBName + '_Virtual] FROM
'
-- Begin Backup File Loop
SELECT
@currentBackupFileIdentifier = MIN([executionOrder]),
@maxBackupFileIdentifier = MAX([executionOrder])
FROM
[#backupFilesToHandle]
WHILE (@currentBackupFileIdentifier <= @maxBackupFileIdentifier)
BEGIN
-- Create Command Line syntax for file copy
SELECT
@commandLine = 'copy "' + [oldFileSpec] + '" "' + [newFileSpec] + '" /Y'
FROM
[#backupFilesToHandle]
WHERE
[executionOrder] = @currentBackupFileIdentifier
-- Truncate the Command Line Results Table
TRUNCATE TABLE [#commandLineResults]
INSERT INTO
[#commandLineResults]
EXEC
[master].[dbo].[xp_cmdshell] @commandLine
-- Record Copy Results
SET @backupCopyResults = @backupCopyResults + '
For command issued=' + @commandLine + '
'
SELECT
@bakCopyResults = @bakCopyResults + '
' + ISNULL([outputLine],'NULL')
FROM
[#commandLineResults]
-- Add this file to the restore script
SELECT
@sql = @sql + 'DISK=N''' + [newFileSpec] + ''','
FROM
[#backupFilesToHandle]
WHERE
[executionOrder] = @currentBackupFileIdentifier
SET @currentBackupFileIdentifier = @currentBackupFileIdentifier + 1
END -- Loop to next Backup File
-- Now that all backup files have been moved and we have added their new locations to the restore script,
-- we now need to remove the trailing comma
SET @sql = LEFT(@sql,LEN(@sql)-1) + '
WITH
'
-- Now we need to add the database files to the restore script
SELECT
@sql = @sql + 'MOVE N''' + [logicalName] + ''' TO N''' + @DATAFILE_RESTORATION_LOCATION + LEFT(@currentDBName,35) + '_Virtual_' + LEFT([logicalName],35) +'.vmdf'','
FROM
[#logicalFilesForlastBackupsTaken]
WHERE
[databaseName] = @currentDBName
-- Remove the trailing comma
SET @sql = @sql + 'NORECOVERY, STATS=1, REPLACE
'
-- Now, we have the files moved and the restoration script created. Next thing to do is to restore the database (using hyperbac)
SET @databaseWasRestored = 0
BEGIN TRY
-- Restore the database
EXEC(@sql)
-- Recover the database
SET @sql = 'RESTORE DATABASE [' + @currentDBName + '_Virtual] WITH RECOVERY, RESTRICTED_USER'
EXEC(@sql)
-- Put the virtual DB in Simple Recovery Model, since we do not need anything higher than that for the DBCC CHECKDB
SET @sql = 'ALTER DATABASE [' + @currentDBName + '_Virtual] SET RECOVERY SIMPLE WITH NO_WAIT'
EXEC(@sql)
SET @databaseWasRestored = 1
END TRY
BEGIN CATCH
SET @errorMessage = @errorMessage + @currentDBName + '
' + @backupCopyResults + '
' + 'Error Number: ' + CONVERT(VARCHAR,ERROR_NUMBER()) + ', Error Message: ' + ERROR_MESSAGE() + '
'
SET @statusMessage = @statusMessage + 'DBCC FOR ' + @currentDBName + ' was not restored properly (error message below).
'
SET @statusCode = @statusCode + 1
END CATCH
-- Only continue if the database was properly restored
IF (@databaseWasRestored = 1)
BEGIN
-- Run DBCC CHECKDB and Save the results to a table
INSERT INTO
[#checkDBResults]
(
[Error],
[Level],
[State],
[MessageText],
[RepairLevel],
[Status],
[DbId],
[Id],
[IndId],
[PartitionId],
[AllocUnitId],
[File],
[Page],
[Slot],
[RefFile],
[RefPage],
[RefSlot],
[Allocation]
)
EXEC('DBCC CHECKDB(''' + @currentDBName + '_Virtual'') WITH TABLERESULTS')
-- Fill in missing information
UPDATE
[#checkDBResults]
SET
[ServerName] = @@SERVERNAME,
[DatabaseName] = @currentDBName
WHERE
[ServerName] IS NULL
-- Drop the restored database
EXEC('DROP DATABASE ['+ @currentDBName + '_Virtual]')
-- analyze all DBCC checkdb results, e-mail out when an error is encountered
IF EXISTS (
SELECT
[ServerName]
FROM
[#checkDBResults]
WHERE
[ServerName] = @@SERVERNAME
AND [DatabaseName] = @currentDBName
AND [MessageText] LIKE 'CHECKDB found 0 allocation errors and 0 consistency errors in database %'
)
BEGIN
SET @statusMessage = @statusMessage + 'DBCC FOR ' + @currentDBName + ' Passed.
'
END -- Condition: A passing entry for this DB in DBCC Results
ELSE IF EXISTS (
SELECT
[ServerName]
FROM
[#checkDBResults]
WHERE
[ServerName] = @@SERVERNAME
AND [DatabaseName] = @currentDBName
)
BEGIN
SET @statusMessage = @statusMessage + 'DBCC FOR ' + @currentDBName + ' Failed! (Check the [#checkDBResults] table)
'
SET @statusCode = @statusCode + 1
END -- Condition: No passing entry for this DB in DBCC Results
ELSE
BEGIN
SET @statusMessage = @statusMessage + 'DBCC FOR ' + @currentDBName + ' was not properly performed (Check Configuration)
'
SET @statusCode = @statusCode + 1
END -- Condition: No entry whatsoever for this DB in DBCC Results
END -- End of "Database was properly restored"
SET @currentDBIdentifier = @currentDBIdentifier + 1
END -- End of "Check if last backup is too old"
END -- Loop to next Database
SET @statusMessage = @statusMessage + '
DBCC CheckDB Process has completed for ' + @@SERVERNAME + ' at ' + CONVERT(VARCHAR,GETDATE(),120) + '
'
IF @statusCode = 0
BEGIN
SET @messageSubject = 'SUCCESS - DBCC CheckDB for ' + @@SERVERNAME
END -- Condition: There were no errors or failures in the consistency checking of this instance
ELSE
BEGIN
SET @messageSubject = 'FAILURE - DBCC CheckDB for ' + @@SERVERNAME
SET @statusMessage = @statusMessage + @errorMessage
END -- Condition: At least one consistency check either failed or resulted in an error
EXEC [msdb].[dbo].[sp_send_dbmail]
@profile_name = @DB_MAIL_PROFILENAME,
@recipients = @EMAIL_RECIPIENTS,
@body = @statusMessage,
@subject = @messageSubject,
@body_format = 'HTML'; |